The performance of deep learning models largely depends on available labelled data. Massive amounts of unlabelled data are captured daily from Earth Observation (EO) satellites, such as the Sentinel-2 constellation. However, annotating imagery is a labour intensive and costly process. Increasingly, self-supervised learning and Foundation Models are being introduced to EO data analysis to increase accuracy and label efficiency. As the EO Foundation Models are based on different architectures and training methodologies, it remains a challenge to evaluate and compare the output performance of their downstream tasks. To this end, in this work, we present the PhilEO Bench which is a novel global stratified framework to evaluate the performance of different EO Foundation Models and their downstream tasks.
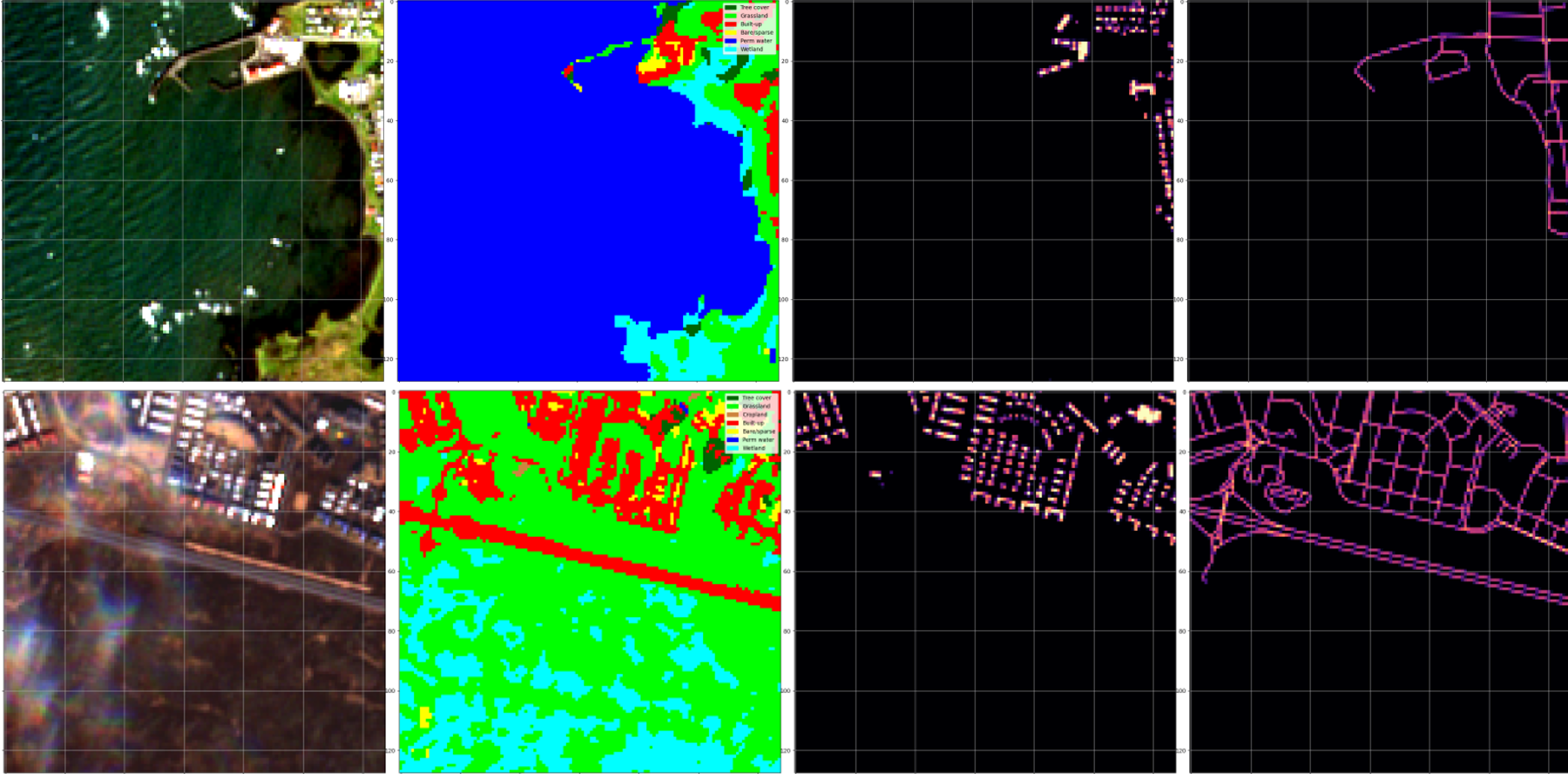
The proposed evaluation framework comprises a new testbed and a novel 400GB global Sentinel-2 dataset containing labels for the three downstream tasks of building density estimation, road segmentation, and land cover classification.
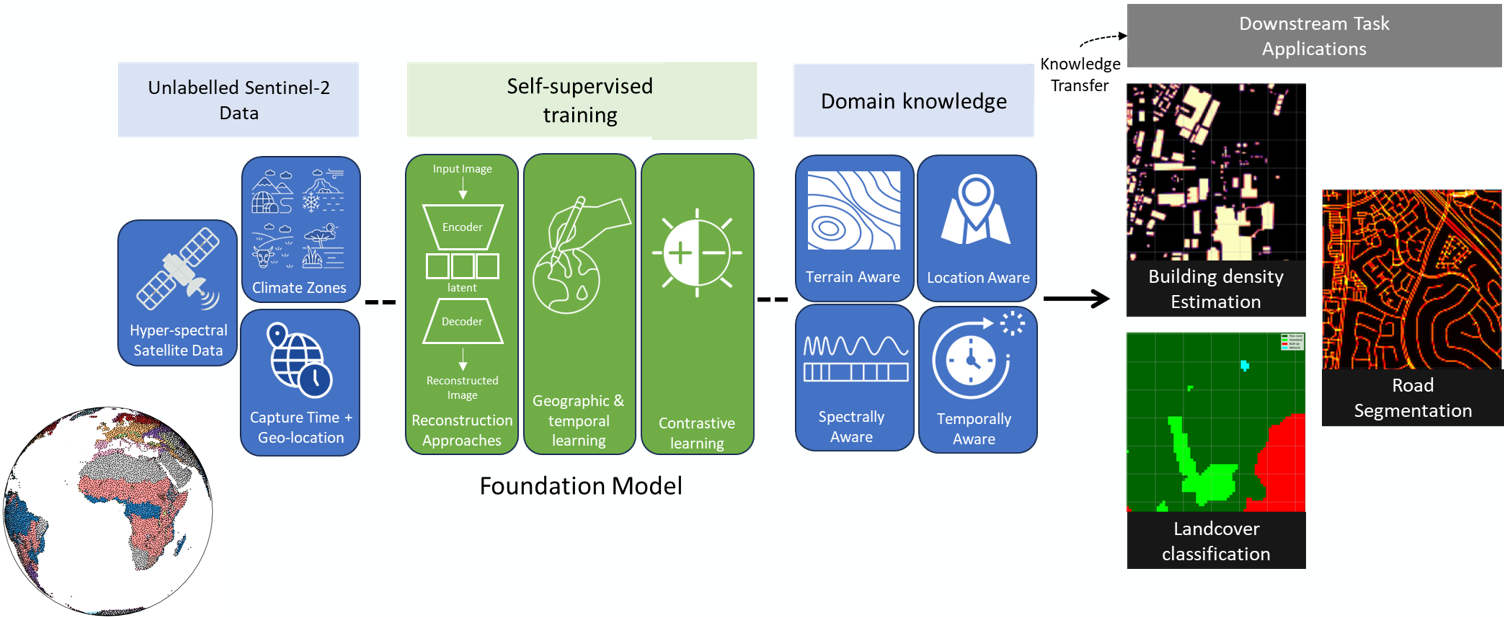
Our framework supports two training configurations: (a) Fine-tuning, and (b) Linear probing. PhilEO also contains U-Net, Vision Transformer (ViT), and Mixer model architectures and supports pre-trained models such as Masked Auto-Encoder (MAE) ViT, and Pre-trained U-Nets, as well as the models Prithvi [2], SatMAE, and SeCo [3]. In addition, our proposed testbed is flexible and easy to use, and an Object Oriented Programming approach is used with an emphasis on modularity, allowing for the easy addition of other new downstream tasks, model architectures, and pre-trained models.
We present experiments using our framework evaluating different EO Foundation Models on downstream tasks, including SeCo, ResNet, Prithvi and SatMAE, based on Masked Auto-Encoder (MAE) and Vision Transformer (ViT) architectures, as well as our proposed PhilEO Bench models based on a U-Net architecture, at multiple n-shots and convergence rates. This work underlines the utility of the proposed evaluation testbed and the importance of having a fair comparison between different EO Foundation Models.

Focusing on the land cover classification downstream task of our PhilEO Bench testbed, we show that comparing the land cover segmentation accuracy of various benchmark and pre-trained models versus the training dataset size, the pre-trained models outperform their randomly initialised fully-supervised counterparts. We also present that the pre-trained (fine-tuned) Geo-Aware U-Net consistently gives the best overall performance. Also, the ViTCNN models seem to underperform when compared to the U-Net architecture.
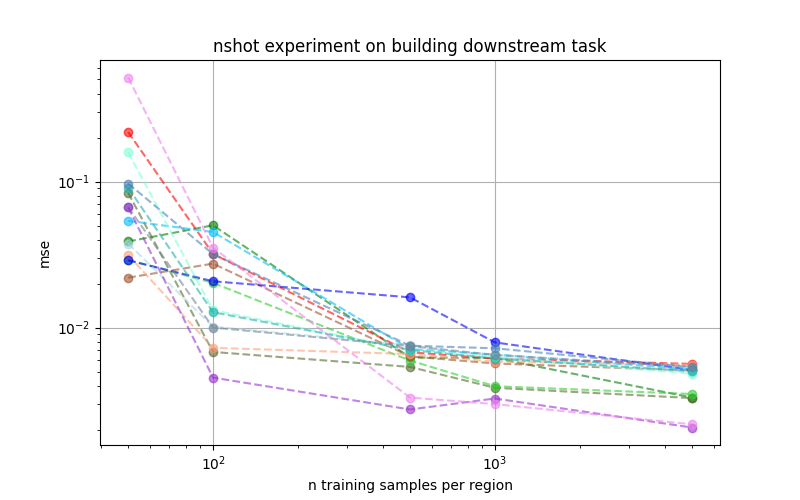
Concerning the building density regression downstream task of the proposed PhilEO Bench testbed, we show that comparing the building density estimation in mean square error (MSE) of the benchmark and pre-trained models versus the training dataset size, the Prithvi-based models result in the lowest MSE scores.